Related: Network Optimization for SPAs and React Apps covers the modern optimization techniques that work with HTTP/2 rather than around HTTP/1.1’s limitations.
In 2012, a frontend developer optimizing a website’s network performance would combine all their JavaScript into one file, combine all their CSS, put icons into a single sprite image, split their static assets across multiple subdomains, and inline small images as base64 strings in CSS. All of these were correct. They were the right things to do.
By 2020, most of them were wrong. Not slightly suboptimal; actively counterproductive on HTTP/2. The underlying constraint they were designed around had been replaced by a better protocol, and the optimizations built for the old constraint became liabilities under the new one.
What this covers: What HTTP/1.1’s connection limit actually meant in practice, how Google’s SPDY experiment led to HTTP/2, what multiplexing changes about the request model, and which of the old practices to stop doing today.
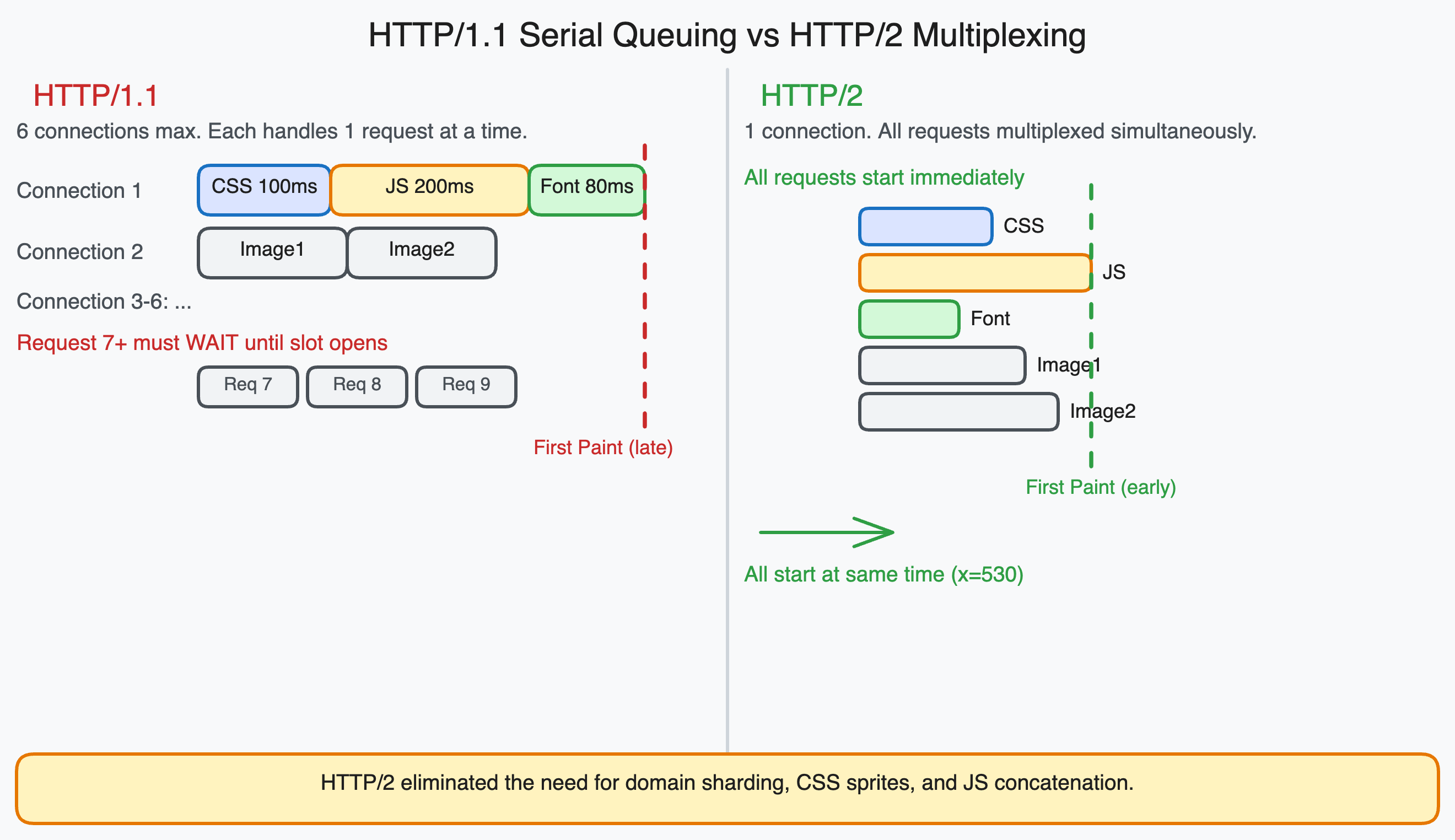
The HTTP/1.1 problem: six connections, one queue per connection
HTTP/1.1 browsers open at most 6 parallel TCP connections to a single domain. Each connection handles one request at a time. If a response is slow, everything queued behind it on that connection waits.
A page loading 30 resources (CSS, JavaScript, fonts, images) from the same origin has to queue 24 of those resources to wait while the first 6 load. When one finishes, the next one in the queue starts. The 30th resource does not begin loading until 24 other resources have each had their turn.
The practical consequence was measured in seconds on typical web pages of that era. Performance engineers spent significant effort on strategies to work around this constraint.
The five workarounds that HTTP/1.1 made necessary
1. Domain sharding. Since browsers limited connections to 6 per domain, the workaround was to host assets on multiple subdomains. static1.example.com, static2.example.com, static3.example.com. Each subdomain got its own 6 connections, effectively multiplying the connection limit by the number of shards.
This worked at the cost of extra DNS lookups (20-120ms each), extra TCP handshakes, and extra TLS negotiations for each new domain. The parallelism gain typically exceeded those costs under HTTP/1.1.
2. CSS sprites. Making a separate HTTP request for each small icon or UI image was expensive under HTTP/1.1 because each request occupied a connection slot for its full round trip. The solution was to combine all icons into a single large image (the sprite sheet) and use CSS background-position to display the relevant portion of the sprite for each icon.
This reduced dozens of requests to one. The downside was that the browser had to download the entire sprite sheet even if only one icon was used on a given page.
3. JavaScript and CSS concatenation. For the same reason, all JavaScript files were concatenated into one file, and all CSS files into another. Two HTTP requests instead of twenty. The cost: browser cache granularity. If any file changed, the entire concatenated bundle was invalidated, even if only one module changed.
4. Inlining small resources as base64. Images smaller than a few kilobytes were often embedded directly in CSS as base64-encoded strings. This eliminated the HTTP request entirely at the cost of increasing the CSS file size and preventing the image from being cached separately.
/* HTTP/1.1 era optimization: inline small images to save a request */
.icon-search {
background-image: url('data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAA...');
}
5. Cookie-free domains for static assets. Browsers send all cookies for a domain with every request to that domain. For static assets like images, fonts, and JavaScript, cookies are irrelevant but they still add bytes to every request header. Serving static assets from a cookieless domain avoided this overhead.
What Google built instead: SPDY
In 2009, Google’s Chrome and infrastructure teams began prototyping a new transport protocol called SPDY (pronounced “speedy”). The goal was to eliminate the performance bottlenecks in HTTP/1.1 at the protocol level rather than working around them with application-level hacks.
SPDY ran over a single TCP connection and used multiplexing: multiple requests could share the same connection simultaneously, with responses interleaved in priority order. There was no queue. A slow response did not block faster responses. The connection limit was no longer the bottleneck.
Google deployed SPDY across their own infrastructure and published the results. Sites serving Google traffic saw measurable page load improvements. The IETF used SPDY as the basis for HTTP/2, which was standardized in 2015. Chrome, Firefox, and all major servers adopted it rapidly.
By 2018, HTTP/2 support was widespread enough that most web traffic ran over it. By 2022, HTTP/2 was the norm and HTTP/1.1 was the exception for major sites.
What multiplexing actually means
HTTP/2 multiplexing means that multiple HTTP requests and responses are interleaved on a single TCP connection. Each request/response pair is broken into frames, and frames from different requests can be intermixed on the wire.
From the browser’s perspective: it can make 50 requests simultaneously over one connection and receive responses as they become ready, regardless of the order requests were made. A fast response to request 30 can arrive before the slow response to request 1.
From the server’s perspective: it sees all requests and can prioritize responses. CSS and critical JavaScript can be sent before images, regardless of which was requested first.
The 6-connection limit no longer constrains parallelism. The browser can have hundreds of in-flight requests over a single HTTP/2 connection.
Why the old optimizations became anti-patterns
Domain sharding now hurts performance. With HTTP/2, all assets should come from the same origin. Multiple origins require multiple connections, and each HTTP/2 connection has overhead: TCP handshake, TLS negotiation, and the HTTP/2 settings exchange. Where HTTP/1.1 made multiple connections valuable, HTTP/2 makes a single connection more efficient.
Sharding across subdomains today means the browser establishes multiple connections when one would serve all resources with better prioritization.
CSS sprites now cost more than they save. HTTP/2 handles many small requests efficiently because they share a connection without queuing behind each other. A sprite sheet that was one efficient request is now one large resource that the browser must download entirely before any icon renders. Individual SVG files can be requested in parallel and only the ones used on the current page need to be downloaded.
Concatenated bundles hurt cache efficiency. The original reason for concatenation was to minimize HTTP requests. Under HTTP/2, 30 small JavaScript modules load nearly as fast as one large concatenated file. But the 30 individual files can be cached independently. When you change one module, only that module’s cache is invalidated. With concatenation, every change invalidates the entire bundle.
This is one of the reasons Vite’s development server can serve unbundled ES modules efficiently: in development over HTTP/2, hundreds of individual module requests perform similarly to serving one large bundle.
Inlining base64 images inflates critical resources. A base64-encoded image in your CSS increases CSS file size and delays rendering of everything that depends on that CSS file. Under HTTP/2, the marginal cost of an extra image request is low enough that it is almost never worth paying the inlining cost.
Cookie-free domains fragment the connection. Serving assets from multiple origins forces multiple HTTP/2 connections. The cookie overhead that domain separation was designed to avoid is minor compared to the connection overhead of the separation itself.
What has replaced the old optimizations
The modern equivalents address the same performance concerns through different mechanisms:
| Old optimization | Modern replacement | Why it changed |
|---|---|---|
| Domain sharding | Single origin, HTTP/2 | HTTP/2 connection is more efficient than multiple HTTP/1.1 connections |
| CSS sprites | Inline SVG, icon fonts, HTTP/2 parallel requests | Small requests are cheap; sprites prevent caching granularity |
| JS/CSS concatenation | Code splitting with long-lived vendor chunks | Cache efficiency matters more than request count |
| Base64 inlining | preload link hints, fetchpriority="high" | Control load priority without embedding in CSS |
| Cookie-free domains | Partitioned cookies, CDN configuration | Modern cookie scoping reduces cross-domain request overhead |
The pattern is consistent: the old optimizations were workarounds for the 6-connection limit. The modern replacements assume multiplexing and optimize for what HTTP/2 actually costs: connection establishment, request priority signaling, and cache efficiency.
How to check if your site uses HTTP/2
Open Chrome DevTools, go to the Network tab, right-click the column headers, and enable the “Protocol” column. Reload the page. Each resource will show its protocol: h2 for HTTP/2, h3 for HTTP/3, or http/1.1 for the older protocol.
If any of your own resources show http/1.1 while others show h2, something in your infrastructure is not upgraded. Common causes: an old reverse proxy in front of your server, a CDN that does not have HTTP/2 enabled for your origin, or an older self-hosted server configuration.
If all resources show h2, the old workarounds above should be removed from your build process if they are still present. They are doing nothing useful and in several cases are actively reducing performance.
One thing that did not change
Request count is less important under HTTP/2, but response size still matters. Every byte downloaded costs bandwidth and parse time. The goal of reducing unnecessary requests shifted to reducing unnecessary bytes. Code splitting, tree shaking, image compression, and font subsetting are all about bytes, not request count, and they matter as much under HTTP/2 as they did under HTTP/1.1.
The optimizations that survived the HTTP/2 transition are the ones that were always about bytes. The ones that disappeared were the ones that were only about request count.