The hardest part of Aadhaar is not storing rows: it is de-duplication: ensuring a person does not receive two identities when the archive already holds over a billion enrollees. Each new application must be checked against an enormous corpus without freezing enrolment.
This post stays at systems intuition, not an insider spec. UIDAI’s public materials, audits, and the general shape of automated biometric identification systems (ABIS) suggest a familiar playbook: templates instead of raw images, cheap filters before expensive matchers, sharded search, redundant engines, and multi-modal biometrics.
Fingerprints and irises as math, not photos
Pairwise comparison of raw fingerprint images does not scale to national throughput. ABIS pipelines extract feature templates, compact representations of minutiae or iris codes. Matching becomes distance or score operations that CPUs and accelerators handle far faster than naive pixel correlation.
That is why de-duplication talks about codes, thresholds, and candidate lists, not “does this photo equal that photo?”
Redundant matchers (the “triple check” idea)
Large identity programmes rarely expose enrolment to a single vendor’s matcher without cross-checks. UIDAI has described multi-engine setups where more than one automated biometric identification stack must agree, within policy thresholds, that a probe is novel before a fresh Aadhaar number is issued, reducing both false merges and false “new person” decisions.
Vendor counts and contracts evolve; the pattern is operational redundancy, not bragging rights about a magic number “three.”
Parallel search on shards
One process scanning a billion-plus templates serially would be measured in hours. Production systems partition the corpus into shards (disjoint subsets, often with biometric or synthetic bucketing), fan out queries to many workers, then aggregate candidate lists and scores under policy thresholds.
Wall-clock latency stays in the seconds class because work is parallel, not because the math got easier.
Fusion across fingers and irises
Single-finger quality varies with age, occupation, and capture conditions. Collecting multiple fingers and irises allows score fusion: a weak print can be rescued by another finger or modality. Fusion tightens de-duplication while keeping false rejects manageable during enrolment.
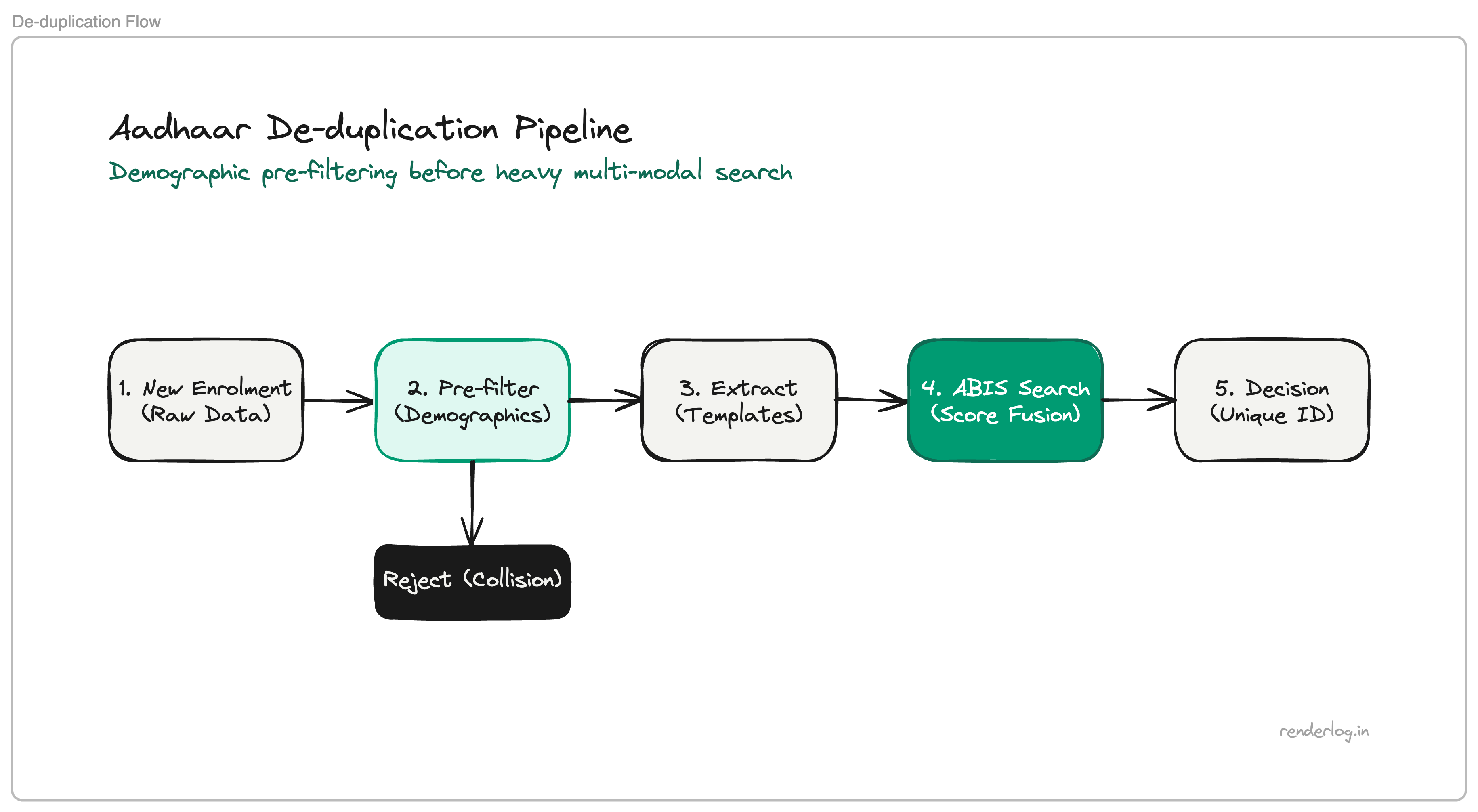
Demographic pre-filtering
Before invoking the heaviest biometric flights, pipelines run cheaper checks: normalized name, date of birth, PIN code or address fields, gender, or whatever the programme stores for collision search.
If demographics already collide strongly with an existing record, the system can short-circuit toward rejection or manual review without paying for full biometric fan-out. Cheap filters first is ordinary query planning at country scale.
Authentication vs. shipping full records
For many verification flows, a relying party needs a decision: whether a biometric or OTP-backed session matches the number on file, not a portrait download. API design pushes toward minimal payloads and match outcomes (exact capabilities have shifted over years of regulation and litigation).
The engineering lesson is traffic shape: return yes/no or scores where possible, not bulk PII copies.
Caveats
Aadhaar sits at the intersection of technology, law, and public debate: scope, mandating, privacy, and surveillance risk are not settled by a pipeline diagram. This article does not argue those points; it only sketches how engineers attack de-duplication complexity.
Official reference: UIDAI.
Takeaway
Uniqueness at population scale is a distributed systems problem disguised as a database problem: templates for speed, shards for parallelism, redundant matchers for trust, fusion for robustness, and demographics to skip work you do not need. Whether that power should exist is policy; how it operates when it does is engineering.